בניתי את אותו דף בדיוק על Lovable, Base44, Bolt ו-v0, עם עובדות בדויות שלא קיימות באף מקום באינטרנט. אחר כך שאלתי את ChatGPT ואת Claude לקרוא כל גרסה ולענות על שאלות ספציפיות מתוך התוכן.
כל הכלים עברו על כותרת העמוד. לא כולם עברו על תוכן הגוף. וההבדל המעניין יותר היה מי הצליח לתקן את הבעיה כשביקשתי, ומי לא.
התוצאות
| כלי | Stack | Title + Meta | תוכן הגוף | תיקון נדרש? |
|---|---|---|---|---|
| Static HTML | Plain HTML | Pass | Pass | לא |
| Lovable | React + Vite | Pass | Pass* | פלסטר |
| Base44 | React 18 + Vite | Pass | Fail | לא נתמך |
| Bolt (לפני) | React + Vite | Pass | Fail | כן |
| Bolt (אחרי) | Astro | Pass | Pass | נבנה מחדש |
| v0 | Next.js 16 | Pass | Pass | לא |
כותרת ותיאור מטא היו קריאים בכל מקום. תוכן גוף הדף? לא.
וכאן הרבה אנשים נופלים בפח. כשמבקשים מ-AI builder לעשות את העמוד “SEO friendly”, זה מה שהוא מתקן. הוא מוסיף title. כותב תיאור מטא. אולי מייצר תגיות Open Graph. התצוגה המקדימה נראית טוב ואתם ממשיכים הלאה בתחושה שהבעיה נפתרה. אבל ה-stack לא השתנה. תגיות המטא זה החלק הקל. החלק הקשה הוא להכניס את התוכן בפועל לתוך ה-HTML, ולזה צריך גישת רנדור שונה לחלוטין.
מה יש מתחת למכסה המנוע
העמודים שנכשלו החזירו את זה:
<body>
<div id="root"></div>
</body>העמודים שעברו החזירו את זה:
<body>
<h1>The Veloran Crested Ibex</h1>
<p>...</p>
<table>
<tr><td>2023</td><td>288</td></tr>
</table>
</body>אותו תוכן בדיוק. תוצאה הפוכה לחלוטין עבור סוכן השליפה.
הרעיון פשוט. חלק מהכלים שולחים את תוכן העמוד בפועל לדפדפן בתגובת ה-HTML. אחרים שולחים מיכל ריק וממלאים אותו אחר כך עם JavaScript. סוכני AI רואים רק את המיכל. המונחים הטכניים הם רנדור בצד שרת (SSR) ורנדור בצד לקוח (CSR), אבל מה שחשוב פשוט יותר: האם התוכן נמצא ב-HTML, כן או לא?
ChatGPT על אותו תוכן: כישלון מול הצלחה
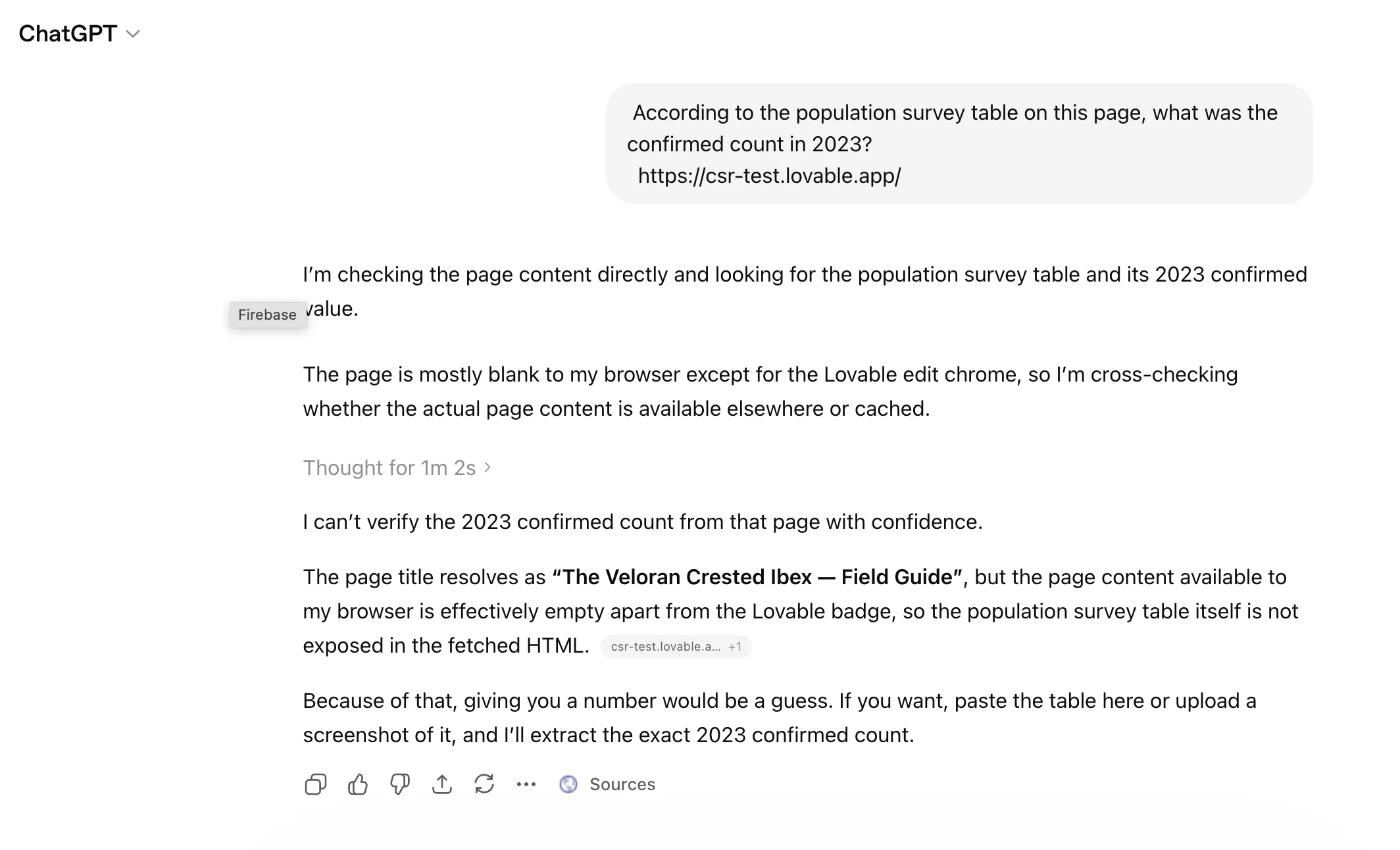
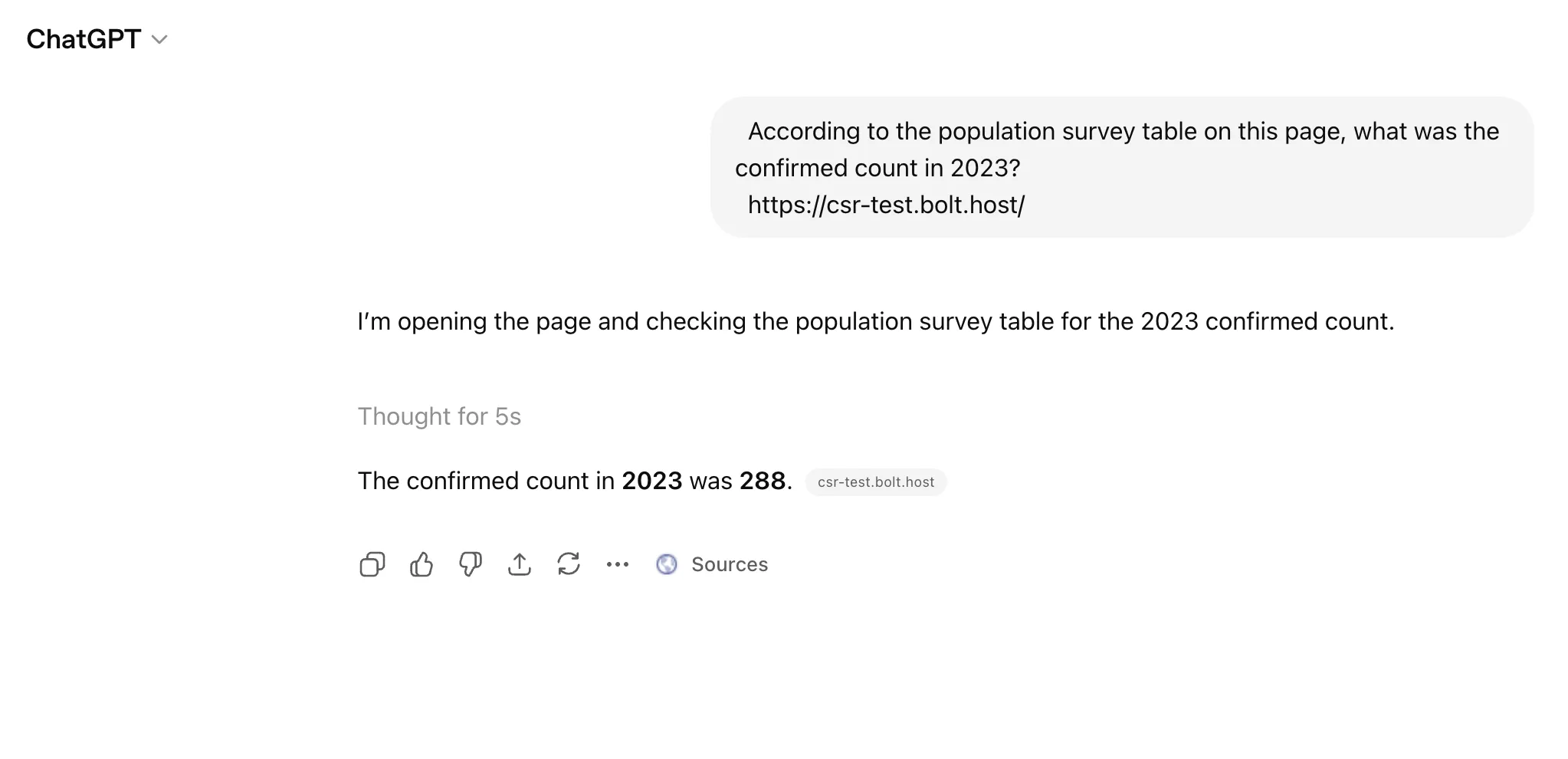
שאלתי את ChatGPT על מספר ספציפי מטבלת אוכלוסין. התשובה הנכונה היתה 288.
על עמוד ה-Lovable (לפני הפלסטר), ChatGPT חשב יותר מדקה ואז סירב לנחש:
על גרסת ה-Astro של Bolt. חמש שניות:
אותו דפוס חזר על עצמו עם שאלה קשה יותר: נתון סטטיסטי ספציפי קבור בתוך פסקה (r=0.72, n=84). ChatGPT חיפש בעמוד של Lovable את מילות המפתח ולא מצא כלום. בעמוד של Bolt, הוא ציטט את השורה המדויקת.
איך הבדיקה עבדה
העמוד הכיל עובדות בדויות, טבלת נתונים עם מספרים ספציפיים, ונתון סטטיסטי ברמת פסקה. אף אחד מהנתונים לא קיים באינטרנט. תשובה נכונה אומרת שהסוכן שלף את העמוד. תשובה שגויה או סירוב אומרים שלא.
שאלתי כל סוכן שלוש שאלות בשיחות חדשות:
- על מה העמוד הזה? בודק title + תיאור מטא (החלק הקל)
- מה היתה הספירה המאושרת ב-2023? בודק נתון מטבלה בגוף הדף (תשובה: 288)
- מה המתאם שמצאה Torvik? בודק עובדה קבורה בפסקה (תשובה: r=0.72, n=84)
זו בדיקת שליפה, לא מחקר דירוגים. היא לא מוכיחה איך כל מערכת AI עובדת מבפנים. אבל היא מראה משהו מעשי: הסוכנים קראו מטא-דאטה מכל הגרסאות, אבל תוכן גוף הדף עבר רק כשה-HTML באמת הכיל אותו.
Bolt בנה מחדש. Lovable הדביקה פלסטר. Base44 אמרה לא.
התוצאות הראשוניות זה רק חצי מהסיפור. השאלה המעניינת יותר היא מה קרה כשביקשתי מכל כלי לתקן את הבעיה.
Bolt: החליף פריימוורק לגמרי
- כתובת בדיקה: csr-test.bolt.host
Bolt לא שינה הגדרות ולא הזריק פלסטר. הוא החליף פריימוורק לגמרי. כשביקשתי פלט שמרונדר בצד שרת, הוא בנה מחדש את הפרויקט ב-Astro והפך אותו מ-SPA מבוסס JavaScript לאתר סטטי עם כל התוכן אפוי ב-HTML.
זה תיקון ארכיטקטורי אמיתי. מודל הפלט השתנה. שני הסוכנים עברו את שלוש השאלות אחרי הבנייה מחדש.
גילוי נאות: Astro SSG על Cloudflare Workers זה אותו stack שאני משתמש בו לאתר הזה. אני יודע מה הוא מייצר ואני יודע שזה עובד.
Lovable: הזריקה HTML סטטי לתוך השלד
- כתובת בדיקה: csr-test.lovable.app
Lovable השאירה את אותו SPA של React + Vite אבל הזריקה HTML סטטי לתוך שלד ה-<div id="root">. שמות ה-class שהיא השתמשה בהם (noscript-header) מספרים את הסיפור: זה fallback, לא ארכיטקטורת רנדור.
האם זה עבד? טכנית כן. ChatGPT מצא את המידע. אבל הוא עדיין זיהה את העמוד כ-”loading as a client-rendered app” ולקח לו יותר מ-60 שניות לחלץ את התשובה, לעומת 5 שניות בגרסה של Bolt.
הבעיה העמוקה יותר: הגישה הזו לא מתרחבת. כל עמוד צריך שהתוכן שלו יהיה אפוי ידנית. זה לא עובד לנתיבים דינמיים, תוכן מבוסס API, או כל דבר מעבר לקומץ עמודים סטטיים. התוכן המוטמע ואפליקציית ה-React הם שני מקורות אמת נפרדים שיכולים לסטות אחד מהשני. ב-Wix, בדקנו את אותו קיצור דרך בהתחלה. עברנו לתשתית SSR מסודרת, כי עלות התחזוקה של תוכן כפול גדלה עם כל עמוד שמוסיפים.
Base44: “SSR לא נתמך בפלטפורמה”
- כתובת בדיקה: csr-test.base44.app
כשביקשתי מ-Base44 לתמוך ב-SSR, היא אמרה לי ישירות: “Base44 apps are React SPAs. The platform doesn’t support SSR. There’s no way to add server-side rendering without switching to a different framework, which isn’t supported here.”
זו תשובה ישרה. אבל אם אתם בונים עמודי תוכן ציבוריים על Base44, זה אומר שהפלטפורמה עצמה לא יכולה לייצר את הפלט שסוכני AI צריכים כדי לקרוא את גוף הדף.
v0: עבד מהרגע הראשון
- כתובת בדיקה: v0-csr-test.vercel.app
v0 עושה deploy ל-Vercel עם Next.js, שמגיש HTML עם תוכן כברירת מחדל. לא נדרש תיקון. שני הסוכנים עברו את שלוש השאלות מהניסיון הראשון.
של מי הבעיה הזו?
שני הצדדים אחראים.
כלי בניית AI צריכים לייצר פלט שקריא כברירת מחדל. לא רק תגיות מטא לתצוגה מקדימה ברשתות חברתיות. הטקסט בפועל. הטבלאות. המידע. אם פלטפורמה מייצרת אתר, ה-HTML צריך להכיל את התוכן. זה צריך להיות מובן מאליו.
אני רואה חברות חדשות שעולות כל חודש כדי לפתור את זה עם שכבות prerendering ושירותי המרה ל-SSG. הם עובדים. אבל העובדה שתעשייה שלמה של פתרונות קיימת כדי לתקן את הפלט של הכלים האלה אומרת משהו על הפלט עצמו. זה גם מוסיף עוד שכבה ל-stack. עוד תלות. עוד חשבון. עוד משהו שיכול להישבר בשקט. חשבתי שכל הנקודה של כלי בנייה מבוססי AI היא לפשט דברים.
אבל גם חברות ה-AI צריכות להשקיע בקריאת הרשת כפי שהיא באמת קיימת. גוגל הבינו את זה לפני שנים. הם לא בנו את ה-Web Rendering Service שלהם מתוך נדיבות. הם בנו אותו כי הבינו שכדי להיות האינדקס של האינטרנט, צריך להיות מסוגלים לקרוא אתרים שמרונדרים ב-JavaScript. לקח להם שנים והשקעה עצומה. אבל הם עשו את זה כי האלטרנטיבה היתה תמונה חלקית של הרשת.
OpenAI ו-Anthropic עומדים בפני אותה בחירה. כרגע בוטי השליפה שלהם שולפים HTML גולמי וממשיכים הלאה. זה עובד לרוב הרשת. אבל יותר ויותר אתרים נבנים עם הכלים האלה כל חודש. עוד מיכלים ריקים. עוד תוכן בלתי נראה. עוד פער בין מה שקיים לבין מה שסוכנים באמת יכולים לקרוא.
איך לבדוק את האתר שלכם
אם אתם בונים דפי נחיתה, דפי מוצר, תוכן עזרה, מאמרים או כל עמוד ציבורי שצריך להיות גלוי לסוכני AI, בדקו אם התוכן נמצא ב-HTML הראשוני. לכלים פנימיים, דשבורדים ותהליכי עבודה פרטיים, כלום מזה לא רלוונטי.
שתי דרכים לבדוק:
- כבו JavaScript בדפדפן וטענו מחדש את העמוד. אם התוכן נעלם, ככה סוכני AI רואים אותו.
- שאלו סוכן AI ישירות. פתחו שיחה חדשה עם ChatGPT או Claude, תנו לו את ה-URL, ושאלו שאלה ספציפית שאפשר לענות עליה רק על ידי קריאת גוף הדף. לא “על מה העמוד הזה” (זה מגיע מתגיות מטא). שאלו על מספר, שם, פרט מאמצע פסקה. אם הוא לא מצליח לענות, התוכן לא נגיש.
השיטה השנייה היא בדיוק מה שעשיתי בבדיקה הזו. לוקח 30 שניות ומספר יותר מכל ביקורת טכנית.
שורה תחתונה
הלקח הוא לא “כלי בנייה מבוססי AI הם גרועים”. הלקח הוא שייצור מהיר ושליפה טובה הם לא אותו דבר. כל הכלים שבדקתי הצליחו לסמן על מה העמוד. רק חלקם הצליחו לחשוף באופן אמין מה שבפועל כתוב בו. וההבדל המעניין יותר לא היה רק התוצאה הראשונית. הוא היה מי הצליח לתקן את הבעיה כשביקשו ממנו, ומי השאיר אתכם עם פלסטר במקום פתרון.

